For a demo of the working app, click here.
For my next project, I wanted to improve upon the parking app I created several weeks ago. The previous app is called SpotFinder, which displays a map of vacant and occupied parking spots using data provided by VIMOC through their API. I liked that service for its ability to direct drivers to find open parking spots on-demand. However, I wished that it could address the underlying need of finding parking, which I could relate to. For example, I often catch myself leaving the house only to be dismayed entering a crowded parking lot, spending up to 10-15 minutes finding parking. If I had known when I left the house that the parking lot would be busy, I would have planned my schedule differently to better allocate my time.
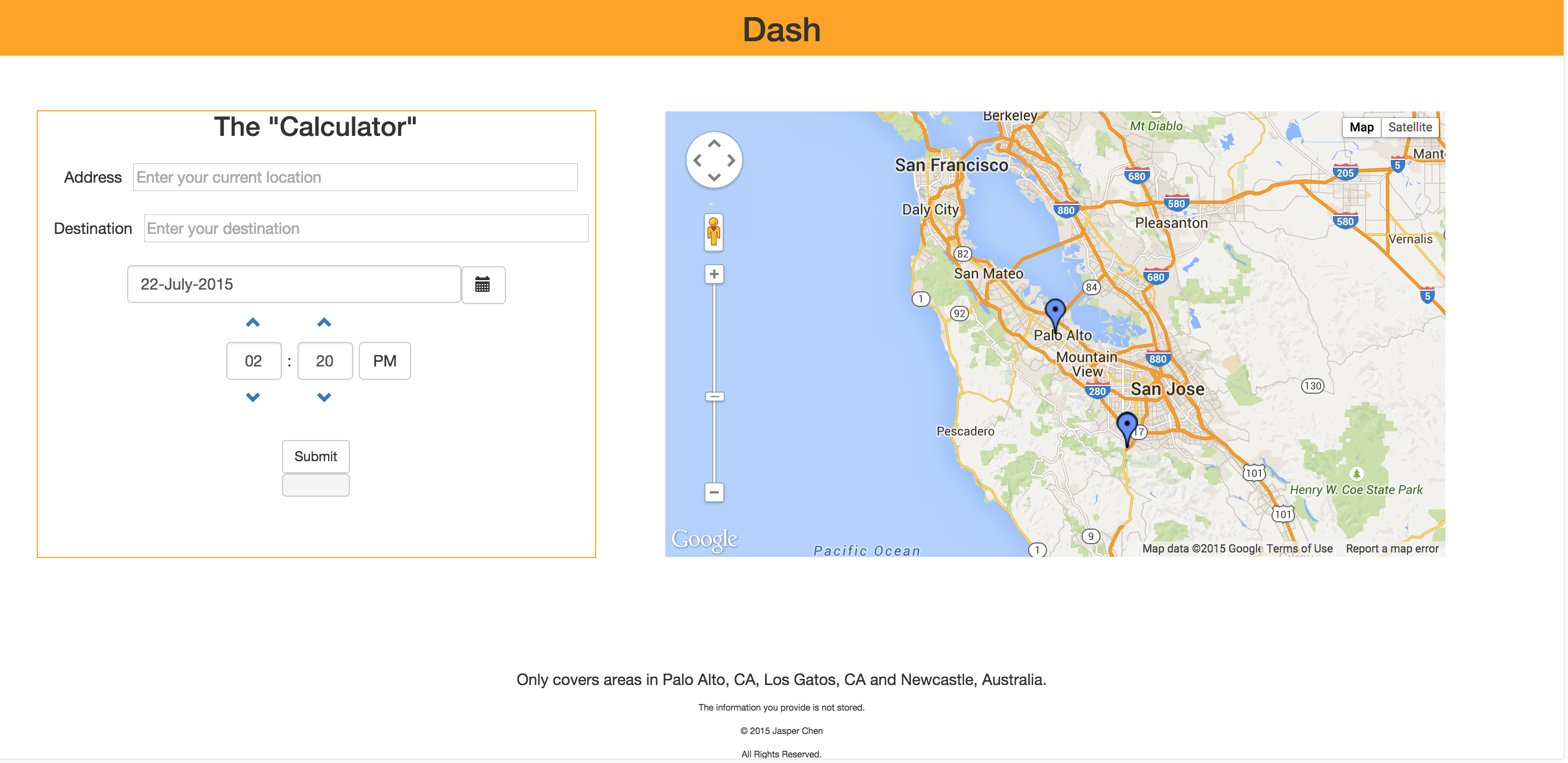
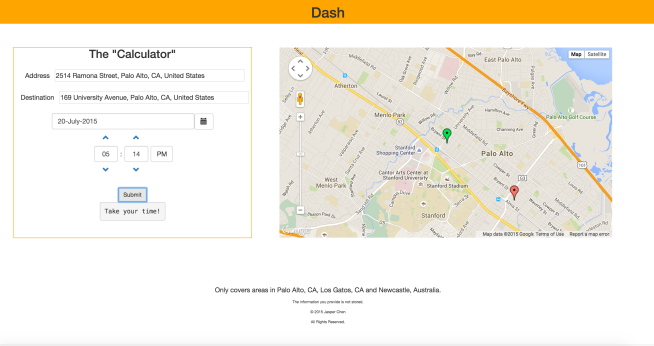
A solution to this parking problem is a web application I designed and built called Dash. Dash is a service that aids as a planner for finding parking around your schedule. Using a simple, one-page interface, Dash forecasts the availability of parking in the area closest to your destination. Simply fill the form on the left, in which you state your trip details, such as your starting location, destination and departure time. To the right is a map of blue markers which indicate the parking zones being kept track of. After you submit the details, the map to the right will update and display the route from your starting location to the nearest parking area of your destination. A red and green pin appears, indicating the user’s starting location and destination.
Like SpotFinder, Dash uses the MEAN stack, which stands for MongoDB, Express.js, Angular.js and Node.js, which collectively, run the back-end and front-end of the service. Angular is a front-end framework, which serves as a broker between the a user and the back-end service. The back-end service is powered by Node and Express, which handles the requests and retrieves data from a MongoDB database of the parking zones and their corresponding occupancy rates.

Since the app uses the MEAN stack, I decided to host my app on Modulus, a web application hosting platform, which enables simple integration between the hosted application and MongoDB database. It also takes care of scaling for an app, so it is a great way to host from start to finish. It is also provides clean dashboards to manage my app’s projects.


But unlike SpotFinder, the project uses Amazon EC2 and S3 to ingest real-time parking and to store them for analysis using Apache Spark, a distributed and fast computing engine. An external EC2 server ingests data from VIMOC’s parking API as well as a real-time weather API and inserts the combined information as a JSON object into the S3 data store. Though the dataset is only 573 MB large, I decided to use Spark for exploration although other analysis tools, such as Pandas, which is a sufficient data analysis tool kit for a dataset this size. I fired up a cluster on my local machine with iPython notebook. The cluster manages tasks to distribute to the datasets, which are partitioned into smaller sets of data on nodes, where the data sets are independently computed. I was able to do this using a handy script I found, which sets up a Spark kernel in iPython notebook. This combination of tools (iPython and Spark) is tremendously beneficial in rapid iteration since iPython is an interactive computational environment (REPL) and Spark is a fast computing engine. In my notebook, Spark was used as a data mining tool to gather a sense of the data collected and to produce a plot of the occupancy rates using matplotlib plotting library in Downtown Palo Alto along Ramona St.

After mining the data for information, I chose a bare-bones model of taking the averages of occupancy rates by hour to forecast future parking occupancy rates The results of the analysis are then stored into the MongoDB database as a key-value store for fast readability from the back-end.
In a more granular description of the application, several components are borrowed from Angular and 3rd party packages in Angular, such as the search boxes that autocomplete text input, is provided through Google’s API and the map, time and date controls which come from a 3rd party package written in Angular. Thanks to these open-sourced libraries, I was able to save time developing while using dashing widgets. Neat! Upon form submission, the form data is passed through an AJAX request from Angular front-end to the Node/Express.js back-end.
The back-end determines the nearest parking zone to the location, and a query to the MongoDB database is sent for the corresponding occupancy rates based on the user’s hour of departure and parking zone. The result is sent back to Node and transformed into a suggestion using thresholding based on its occupancy rate. For instance, if a zone reports a 80% or more, then the app suggests to leave soon assuming that it will take quite some time to find parking.
There are some things I would like to improve upon, for instance, the predictive model and automation of the app. With the current version, I had purposefully designed it to be simple due to time constraints. In future iterations, I plan on incorporating a more developed machine learning model, training on features such as the day of the week, time of day and location. In addition, I would also like to integrate Spark into the back-end, where Spark can read from an updated dataset of parking data in real-time and forecast occupancy rates.




